
مور تردز از Lushan برای گیمینگ و Huashan با پیشرفت تا ۶۴ برابر رونمایی کرد
Moore Threads بهطور رسمی دو پردازنده گرافیکی جدید خود با نامهای Lushan برای بازی و Huashan ویژه هوش مصنوعی را معرفی کرد. این محصولات بر معماری نسل بعدی Flower Harbor یا هوگانگ تکیه دارند و شرکت وعده ارتقای عملکرد چشمگیر داده است. طبق ادعا، Lushan میتواند در بازیهای AAA تا پانزده برابر سریعتر باشد، رهگیری پرتو را پنجاه برابر بهبود دهد و پردازشهای هوش مصنوعی را شصتوچهار برابر ارتقا بخشد. افزونبراین، ظرفیت حافظه چهار برابر افزایش مییابد.
معماری Flower Harbor شامل واحد محاسباتی بهینهشدهای است که تراکم پردازشی را پنجاه درصد افزایش میدهد و راندمان انرژی را ده درصد ارتقا میبخشد. این معماری از فرمتهای مختلف FP4 تا FP64 پشتیبانی میکند و فرمتهای اختصاصی MTFP6 و MTFP4 را برای دقت پایین ترکیبی ارائه میدهد. افزونبراین مدل برنامهنویسی غیرهمگام و سیستم اتصال بسیار بزرگی ارائه شده که GPUهای Huashan نیز از آن پشتیبانی میکنند.

به لطف فناوری MTLink ظرفیت مقیاسپذیری بسیار بالایی فراهم شده و امکان اتصال بیش از صد هزار GPU در یک خوشه ایجاد میشود. فرمتهای پردازشی سازگار شامل FP64، FP32، TF32، FP16، BF16، FP8، FP6، FP4، INT8، MTFP8، MTFP6 و MTFP4 هستند. این طراحی اجازه میدهد تا معماری جدید در حوزههای متفاوت مانند محاسبات سنگین، دقت ترکیبی و اجرای مدلهای هوش مصنوعی انعطاف بالایی ارائه دهد.
Lushan بهعنوان جانشین سری مصرفی MTT معرفی شده و جایگزین مدلهای MTT S80 و S90 خواهد شد. هرچند جزئیات فنی کامل منتشر نشده، اما عملکرد مورد انتظار اعلام شده شامل افزایش پانزدهبرابری سرعت بازیهای AAA، شصتوچهار برابر قدرت پردازش هوش مصنوعی، شانزده برابر سرعت هندسی، چهار برابر نرخ تکسچر، هشت برابر سرعت دسترسی اتمی حافظه و پنجاه برابر توان رهگیری پرتو است.
پشتیبانی از DirectX 12 Ultimate نیز در این معماری افزوده شده تا ضعفهای نسل قبلی رفع شود. همچنین معماری UniTE برای رندر مبتنی بر هوش مصنوعی معرفی شده و موتور تازه رهگیری پرتو توسعه یافته تا مسیر رندر عصبی و Path Tracing هموار شود. این تغییرات بیانگر آن است که Lushan میخواهد فضای گرافیکی پیشرفته را با محوریت بازی و رندر هوشمند هدف قرار دهد.
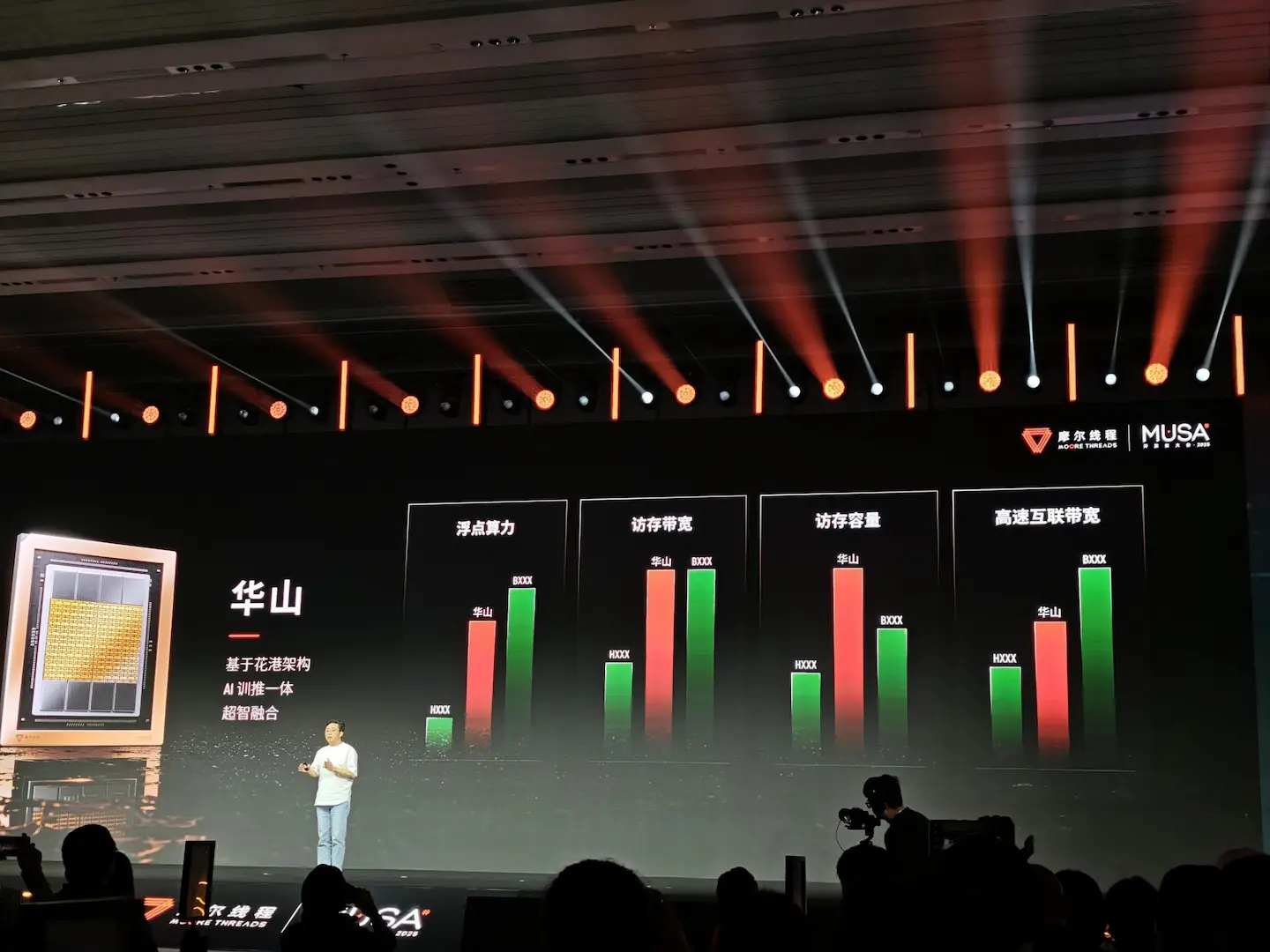
در مورد گرافیکی هوش مصنوعی Huashan، این پردازنده از دو چیپلِت تشکیل شده و دارای هشت محل HBM است. Moore Threads قدرت پردازش آن را با NVIDIA Hopper و Blackwell مقایسه میکند؛ عملکرد شناور نزدیک به Blackwell B200 ارزیابی شده، پهنای باند مشابه عنوان میشود و ظرفیت دسترسی حافظه حتی بالاتر از Blackwell است. این GPU با هدف رقابت جدی در حوزه دیتاسنتر طراحی شده است.

ظرفیت حافظه در نسل جدید چهار برابر خواهد بود و باتوجه به ظرفیت شانزده گیگابایت GDDR6 در مدلهای S80 و S90 انتظار میرود تا شصتوچهار گیگابایت حافظه فراهم شود. این پیشرفت همراه با معماری جدید نشان میدهد Moore Threads بهدنبال افزایش قابلتوجه توان برای مدلهای هوش مصنوعی بزرگ و پردازشهای پیچیده است و میخواهد محدودیتهای ذخیرهسازی نسل پیشین را برطرف سازد.
نخستین کارتهای Lushan سال ۲۰۲۶ عرضه میشوند و GPUهای هوش مصنوعی نیز تقریباً در همین دوره معرفی خواهند شد. Moore Threads همچنین عملکرد GPU مدل MTT S5000 را نمایش داده است؛ تراشهای که برای رقابت با سری Hopper انویدیا توسعه یافته و توانسته در DeepSeek V3 به سرعت هزار توکن بر ثانیه در Decode و چهار هزار توکن بر ثانیه در Prefill برسد و بخش مهمی از سرور MTT C256 supernode باشد.



