
شرکت Sina از مدل متنباز VibeThinker-3B با عملکردی هم سطح مدلهای چند صد برابر بزرگتر رونمایی کرد
شرکت Sina از مدل زبانی متنباز VibeThinker-3B رونمایی کرده؛ مدلی با تنها ۳ میلیارد پارامتر که طبق گزارش فنی منتشر شده، در آزمونهای دشوار ریاضی و برنامهنویسی عملکردی همسطح برخی از بزرگترین مدلهای هوش مصنوعی جهان ارائه میدهد. این مدل در بنچمارکهایی مانند AIME26 به نتایجی نزدیک DeepSeek V3.2 و Kimi K2.5 رسیده، در حالی که این رقبا بین ۲۰۰ تا ۳۳۳ برابر پارامتر بیشتری دارند.
سینا هدف از توسعه VibeThinker-3B را بررسی این موضوع عنوان کرده که یک مدل زبانی برای رقابت در بالاترین سطح واقعاً به چه میزان توان محاسباتی نیاز دارد. نسخه قبلی این پروژه با نام VibeThinker-1.5B در نوامبر ۲۰۲۵ معرفی شده بود و نسخه جدید تلاش میکند نشان دهد یک مدل کوچک میتواند به عملکردی در سطح بهترین مدلهای بازار برسد، نه اینکه فقط نسبت به اندازه خود موفق ارزیابی شود.
بر اساس نتایج منتشرشده، VibeThinker-3B در شش بنچمارک ریاضی و برنامهنویسی در محدوده عملکرد پنج مدل مطرح کنونی شامل جمنای ۳ پرو، GLM-5 و Claude Opus 4.5 قرار گرفته است. در وظایفی که پاسخ آنها ساختار مشخص و امکان راستیآزمایی دارند، مانند المپیادهای ریاضی یا چالشهای برنامهنویسی، این مدل توانسته با سامانههای بسیار بزرگتر رقابت کند و نتایج قابل توجهی به ثبت برساند.
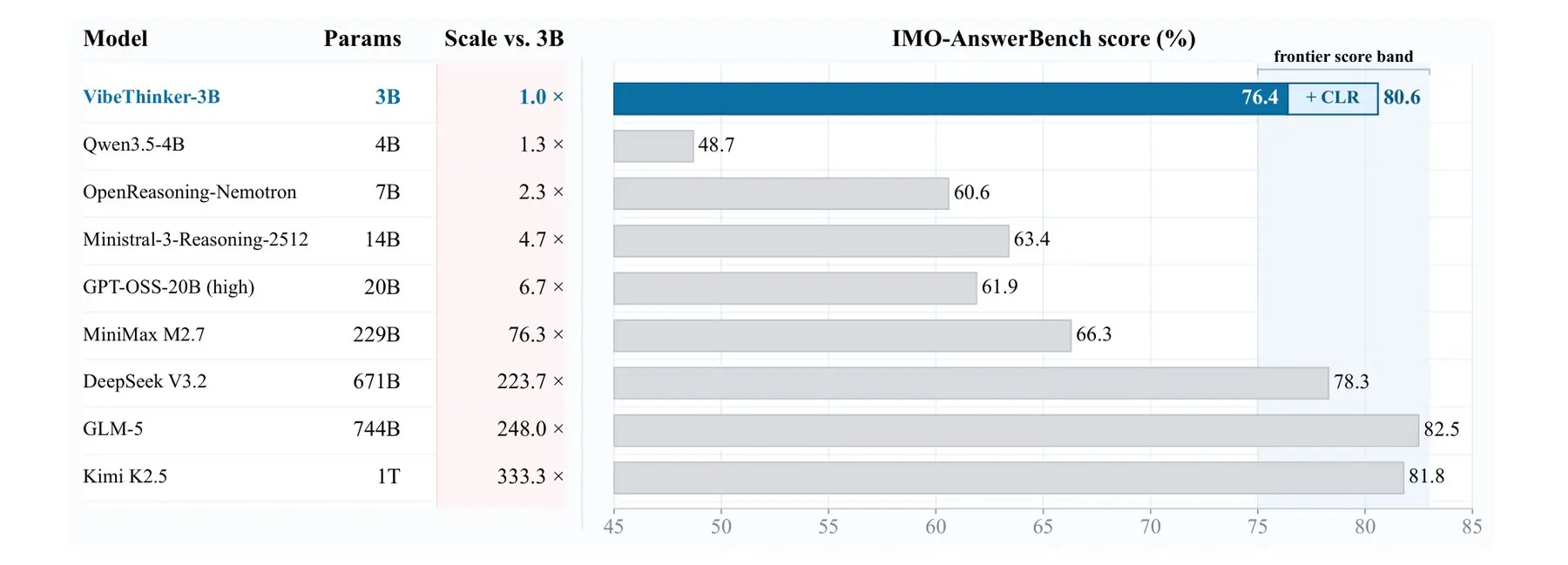
یکی از بهترین نتایج این مدل در LiveCodeBench ثبت شده؛ جایی که VibeThinker-3B توانسته از تمام مدلهای دارای کمتر از ۲۰ میلیارد پارامتر پیشی بگیرد. با این حال نتایج نشان میدهد این موفقیت به همه حوزهها تعمیم پیدا نمیکند. در بنچمارک دانشمحور GPQA-Diamond که به اطلاعات گسترده در موضوعات مختلف وابسته است، مدل فاصله محسوسی با رقبای بسیار بزرگتر خود دارد.
برای بررسی احتمال آلودگی دادههای آموزشی، پژوهشگران عملکرد مدل را در مسابقات LeetCode برگزارشده بین اواخر آوریل تا اواخر مه ۲۰۲۶ ارزیابی کردند؛ رقابتهایی که پس از پایان آموزش مدل برگزار شده بودند. VibeThinker-3B در نخستین تلاش خود موفق به حل ۱۲۳ مسئله از مجموع ۱۲۸ مسئله شد و عملکردی فراتر از GPT-5.2، Qwen3-Max، Kimi K2.5 و Claude Opus 4.6 ثبت کرد.
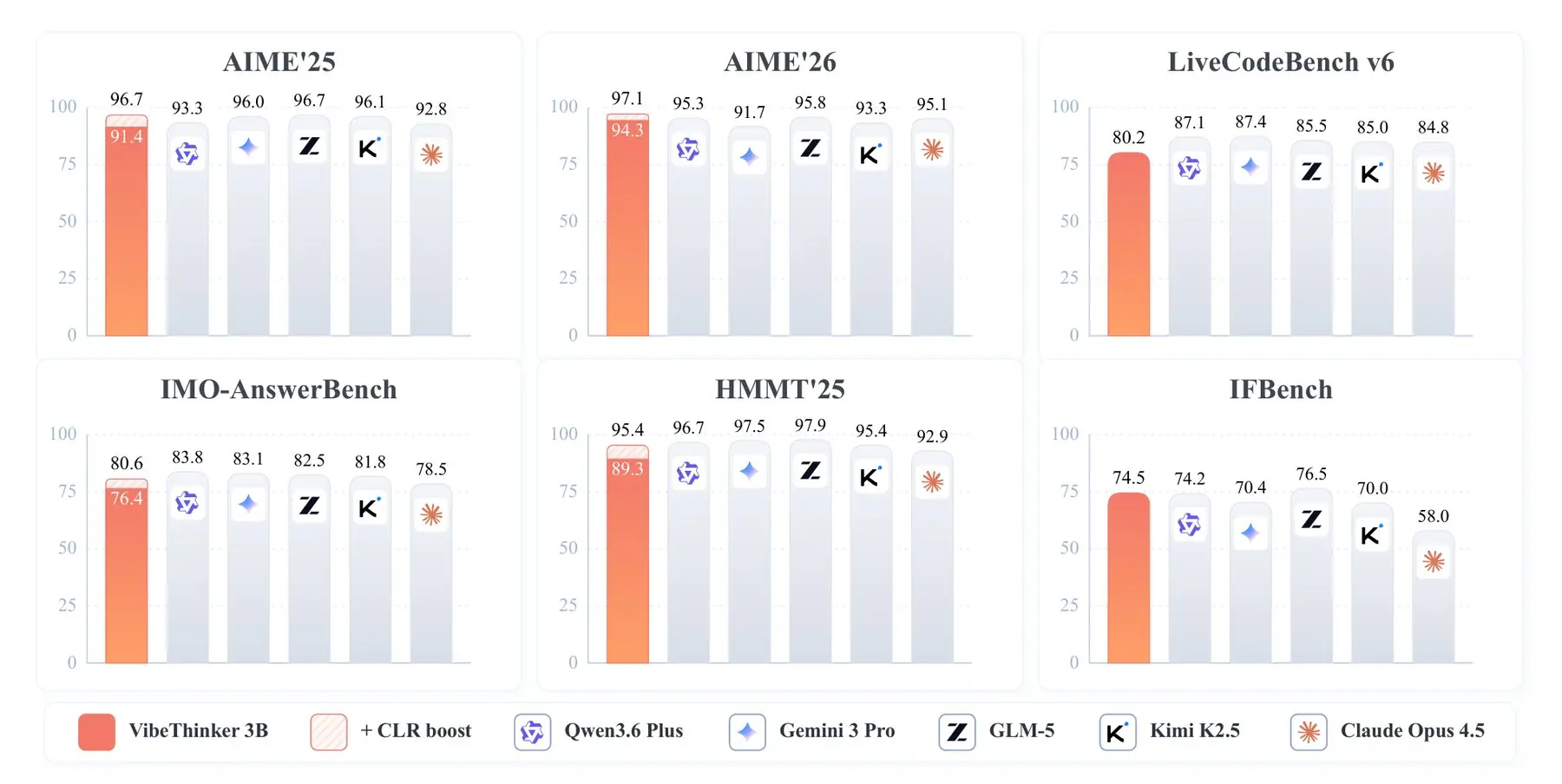
در این ارزیابی تنها GPT-5.3-Codex، Gemini 3.1 Pro و Gemini 3 Flash عملکردی اندکی بهتر از VibeThinker-3B داشتند. پژوهشگران این نتایج را نشانهای میدانند که موفقیت مدل صرفاً حاصل حفظ کردن دادههای آموزشی نیست. به اعتقاد آنها عملکرد این مدل در آزمونهایی که پس از پایان فرایند آموزش برگزار شدهاند، اعتبار نتایج بهدستآمده را تا حد زیادی تقویت میکند.
VibeThinker-3B بر پایه مدل Qwen2.5-Coder-3B شرکت Alibaba توسعه یافته، اما سینا تأکید میکند مهمترین عامل پیشرفت آن مرحله Post-training بوده است. این فرایند با تنظیم دقیق نظارتشده آغاز میشود و آموزش مدل را در حوزههایی مانند ریاضیات، برنامهنویسی و گفتوگوی عمومی پوشش میدهد. سپس مدل برای حل مسائل دشوار و استدلالهای چندمرحلهای بهصورت اختصاصی بهینهسازی میشود.
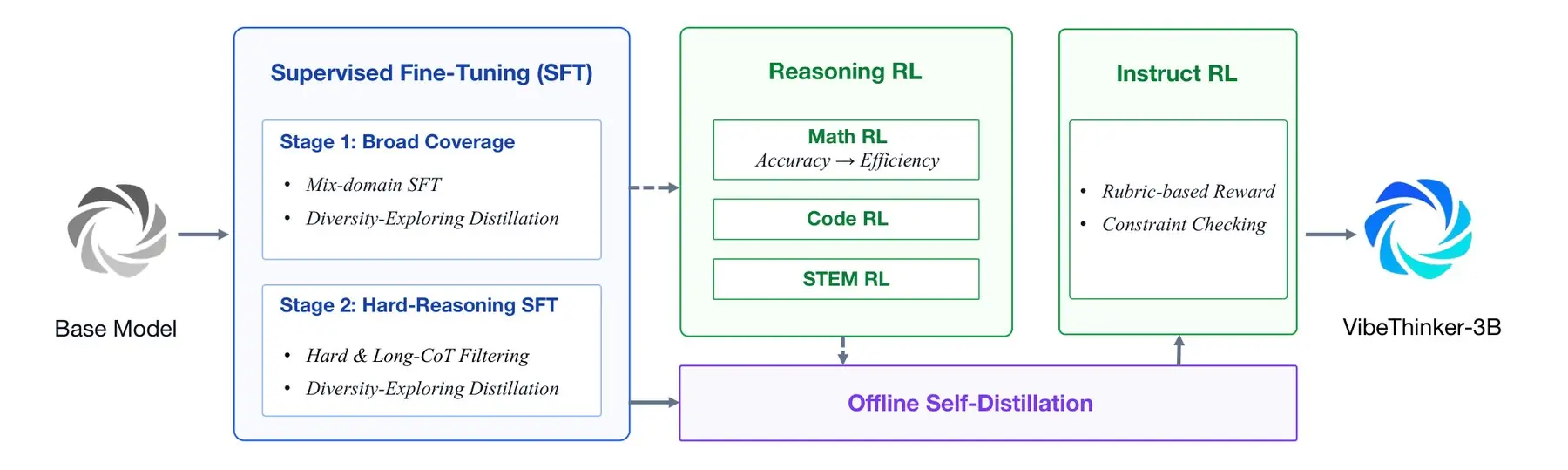
پس از آن یادگیری تقویتی بهصورت مرحلهای برای ریاضیات، برنامهنویسی و علوم پایه یا STEM اجرا میشود. در ادامه فرایند Self distillation مهارتهای بهدستآمده در مراحل مختلف را در یک مدل واحد ادغام میکند و در پایان نیز مرحلهای برای بهبود میزان پایبندی مدل به دستورهای کاربر انجام میشود. پژوهشگران معتقدند کیفیت آموزش، دادهها و سیگنالهای ارزیابی از تعداد پارامترها مهمتر هستند.
تیم توسعهدهنده بر اساس این نتایج فرضیهای با عنوان «Parametric Compression Coverage Hypothesis» ارائه کرده و طبق این دیدگاه، استدلال منطقی بر مجموعهای محدود از الگوهای تکرارشونده مانند جستوجو، بررسی شرایط، اصلاح خطا و ترکیب نتایج متکی است؛ بنابراین میتوان آن را در مدلهای کوچک فشرده کرد. در مقابل پاسخگویی به پرسشهای دانشی به پوشش گسترده اطلاعات نیاز دارد و همچنان به تعداد زیاد پارامترها وابسته است.
پژوهشگران میگویند این یافتهها نقش مدلهای کوچک را بازتعریف میکند و نشان میدهد آنها دیگر تنها گزینهای ارزان برای کاهش هزینه استنتاج نیستند، بلکه به مسیری مستقل در پژوهشهای هوش مصنوعی تبدیل شدهاند. VibeThinker-3B اکنون بهصورت متنباز در Hugging Face و GitHub منتشر شده است. آنها همچنین به موفقیت Qwen3.6-27B و Falcon H1R 7B اشاره میکنند و معتقدند نتایج جدید، فرضیههای پیشین درباره ناتوانی مدلهای کوچک در استدلال چندمرحلهای را به چالش میکشد.



