
علیبابا از Qwen3.5 با انتشار نسخهی Qwen3.5 397B A17B رونمایی کرد
نسخه رسمی Qwen3.5 با انتشار وزنهای باز نخستین مدل این خانواده یعنی Qwen3.5 397B A17B معرفی شد. این مدل بومی vision language در ارزیابیهای استدلال، کدنویسی، قابلیتهای ایجنت و درک چندوجهی عملکرد برجستهای ثبت کرده. معماری آن ترکیبی از توجه خطی مبتنی بر Gated Delta Networks و sparse mixture of experts است. با وجود ۳۹۷ میلیارد پارامتر، تنها ۱۷ میلیارد در هر گذر فعال میشود و پشتیبانی زبانی از ۱۱۹ به ۲۰۱ زبان و گویش رسیده است.
در بخش بنچمارکها، HLE-Verified بهعنوان نسخه بازبینیشده Humanity’s Last Exam با پروتکل تأیید جزءبهجزء و طبقهبندی ریزدانه خطاها بهصورت متنباز منتشر شده است. در TAU2 Bench تنظیمات رسمی رعایت شده اما در دامنه خطوط هوایی اصلاحات Claude Opus 4.5 اعمال شدهاند. MCP-Mark از سرور GitHub MCP نسخه v0.30.3 استفاده میکند و پاسخهای ابزار Playwright در ۳۲ هزار توکن محدود شدهاند.
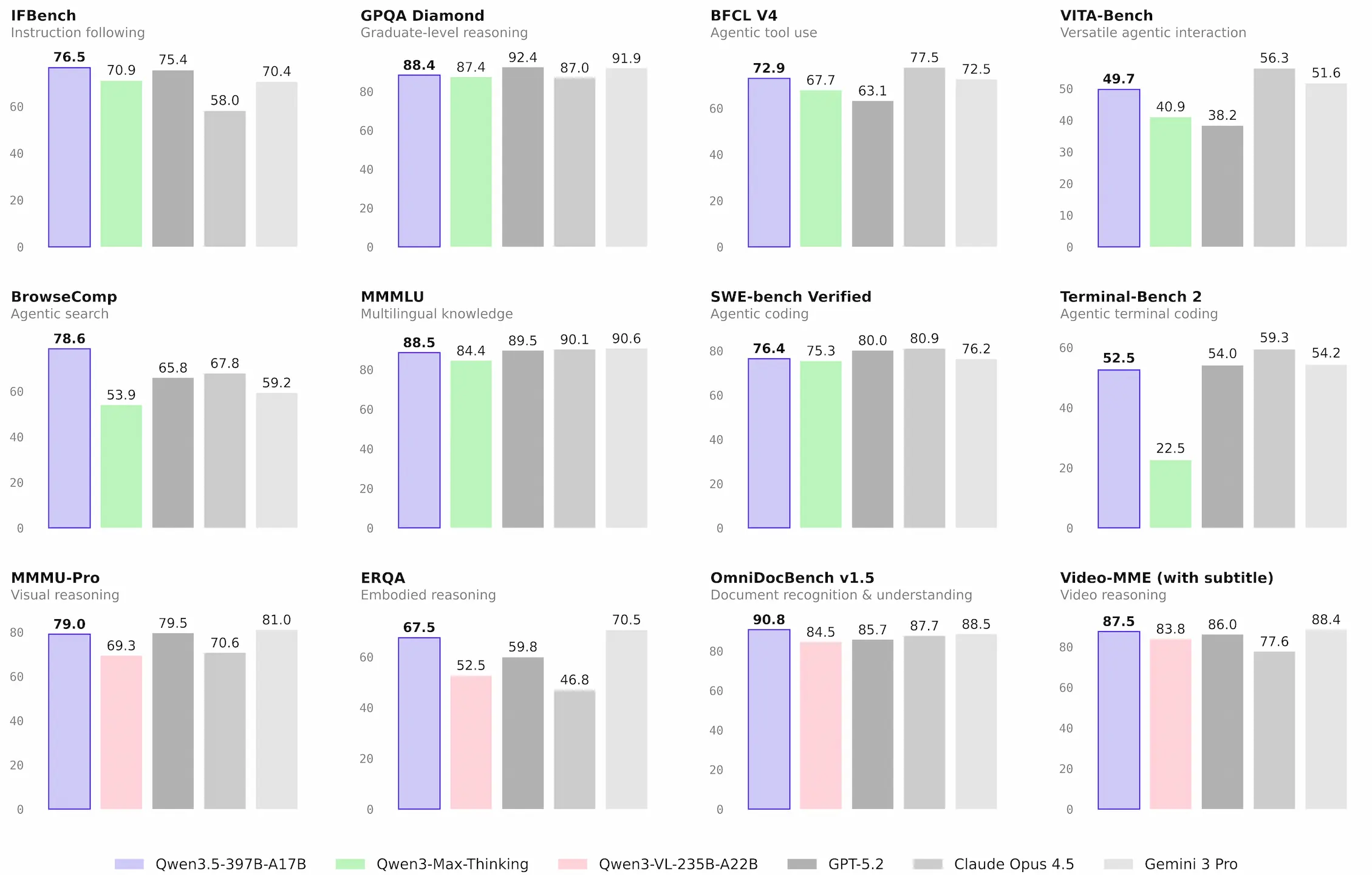
ایجنتهای جستوجوی مبتنی بر این مدل عمدتاً از راهبرد context folding با پنجره 256k استفاده میکنند؛ با رسیدن طول پاسخهای ابزاری به آستانه مشخص، تاریخچه قدیمی حذف میشود. در BrowseComp روش ساده امتیاز ۶۹.۰ و راهبرد discard-all مشابه DeepSeek-V3.2 و Kimi K2.5 امتیاز ۷۸.۶ کسب کرده است. WideSearch بدون مدیریت زمینه اجرا شده و MMLU-ProX میانگین دقت ۲۹ زبان را گزارش میدهد.
در WMT24++ که نسخه دشوارتر WMT24 پس از برچسبگذاری و بازمتعادلسازی است، میانگین امتیاز ۵۵ زبان با XCOMET-XXL اعلام شده است. MAXIFE دقت را در ۲۳ تنظیم شامل پرامپتهای اصلی انگلیسی و چندزبانه ارائه میدهد. در MathVision پرامپت ثابت با قالب \boxed{} استفاده شده و برای سایر مدلها بهترین نتیجه با یا بدون این قالب لحاظ شده است؛ خانههای خالی نشاندهنده نبود دادهاند.
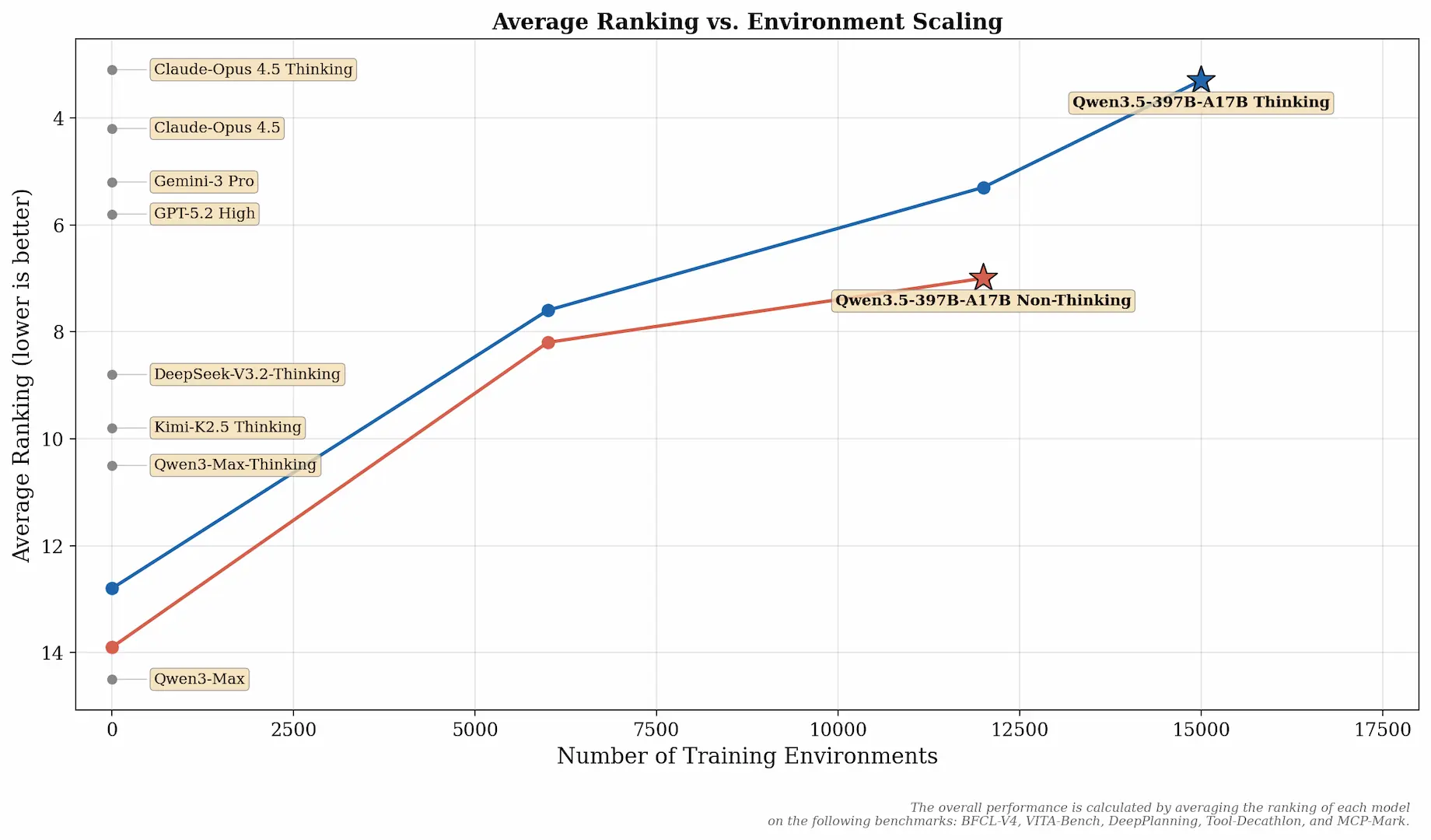
در ارزیابیهای BabyVision و V* نتایج با فعال بودن Code Interpreter گزارش شدهاند که بدون آن بهترتیب ۴۳.۳ و ۹۱.۱ ثبت میشود. توسعهدهندگان اعلام کردهاند بهبودهای Qwen3.5 نسبت به سری Qwen3 حاصل مقیاسدهی گسترده محیطهای RL با تمرکز بر افزایش دشواری و تعمیمپذیری بوده است. عملکرد کلی با میانگین رتبه در BFCL-V4، VITA-Bench، DeepPlanning، Tool-Decathlon و MCP-Mark محاسبه شده است.
در محور قدرت، مدل با حجم بسیار بیشتری از توکنهای بینایی متن و دادههای غنیشده چینی، انگلیسی، چندزبانه و STEM تحت فیلترینگ سختگیرانه آموزش دیده و به برابری عملکرد با Qwen3 Max Base بالای یک تریلیون پارامتر رسیده است. در محور کارایی، معماری Qwen3 Next شامل MoE پراکندهتر، ترکیب Gated DeltaNet و Gated Attention، بهینهسازیهای پایداری و پیشبینی چندتوکنی است که گذردهی ۸.۶/۱۹ برابر Qwen3 Max را در 32k/256k ارائه میدهد.

گذردهی دیکودینگ این مدل همچنین ۳.۵ و ۷.۲ برابر Qwen3 235B A22B در همان طول زمینه اعلام شده است. از نظر چندمنظورهبودن، ادغام زودهنگام متن و بینایی و گسترش دادههای بصری، STEM و ویدئویی باعث پیشیگرفتن از Qwen3 VL در مقیاس مشابه شده است. واژگان ۲۵۰ هزار توکنی نسبت به ۱۵۰ هزار قبلی، کارایی رمزگذاری و رمزگشایی را بین ۱۰ تا ۶۰ درصد در بیشتر زبانها بهبود داده است.
زیرساخت ناهمگن آموزش با جداسازی موازیسازی بخشهای بینایی و زبان، از ناکارآمدی رویکرد یکنواخت جلوگیری کرده و با فعالسازیهای پراکنده، همپوشانی محاسباتی ایجاد میکند که نزدیک به ۱۰۰ درصد گذردهی آموزش روی دادههای متن، تصویر و ویدئو فراهم میسازد. خط لوله بومی FP8 برای فعالسازیها، مسیردهی MoE و GEMM استفاده میشود و با حفظ BF16 در لایههای حساس، حدود ۵۰ درصد کاهش حافظه و بیش از ۱۰ درصد افزایش سرعت ایجاد میکند.
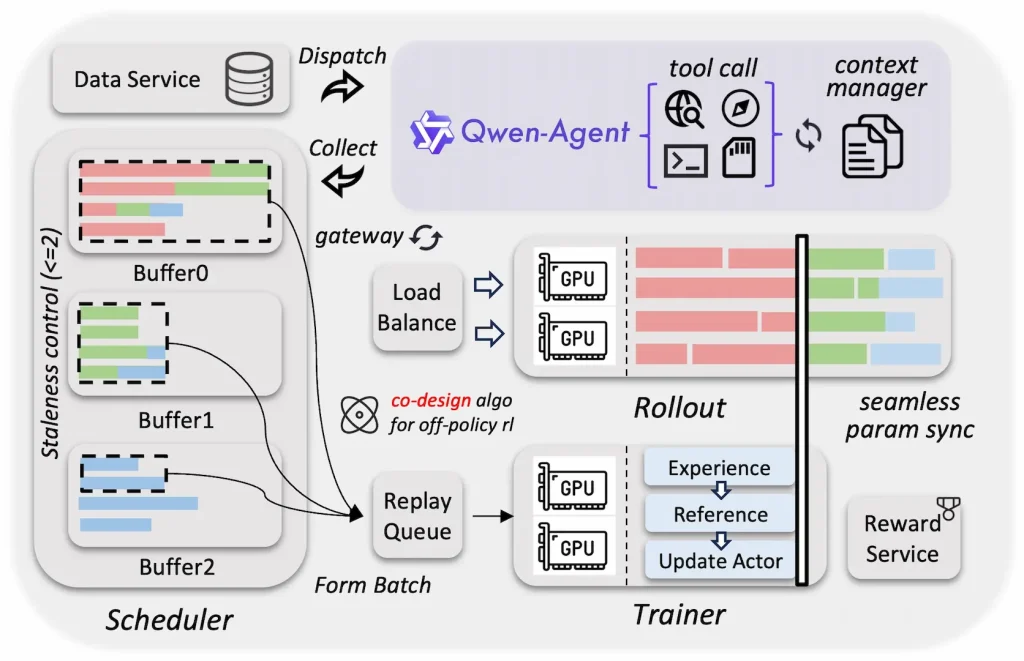
چارچوب RL ناهمگام و تفکیکشده آموزش استنتاج برای همه اندازههای Qwen3.5 طراحی شده و بهرهوری سختافزاری بالاتر، توازن بار پویا و بازیابی خطای ریزدانه را ممکن میکند. تکنیکهایی مانند آموزش سرتاسری FP8، rollout router replay، دیکودینگ حدسی و قفلگذاری rollout چندنوبتی گذردهی و سازگاری را بهبود میدهند. این همطراحی سیستم و الگوریتم، کهنگی گرادیان و ناهمگنی داده را کنترل کرده و افزایش سرعت سرتاسری ۳ تا ۵ برابری را رقم زده است.
Qwen3.5 در Qwen Chat با سه حالت Auto، Thinking و Fast عرضه شده است؛ Auto از تفکر تطبیقی همراه جستوجو و Code Interpreter بهره میبرد، Thinking برای مسائل دشوار عمیق عمل میکند و Fast پاسخ فوری بدون صرف توکن تفکر میدهد. مدل Qwen3.5 Plus از طریق Alibaba Cloud ModelStudio در دسترس است و با پارامترهای enable thinking و enable search قابلیت استدلال و جستوجوی وب فعال میشود.
API بایلیان با ابزارهایی مانند Qwen Code، Claude Code، Cline، OpenClaw و OpenCode برای تجربه vibe coding ادغام میشود. مدل بهعنوان ایجنت چندوجهی توانایی تفکر، جستوجو، استفاده از ابزار و ساخت خروجی را دارد و در فرانتاند وب دستورهای ساده را به کد تبدیل میکند. با ورودی یک میلیون توکن، پردازش دو ساعت ویدئو، مدلسازی روابط فضایی پیکسلی، شمارش دقیق اشیا و کاهش خطای پرسپکتیو را در کاربردهایی مانند رانندگی خودران و ناوبری رباتیک ممکن میسازد.



